Scaling with AI is Hard because AI is Lazy

TL;DR
I’ve merged fifty cleanup, fix, and audit PRs against tabiji.ai in the last five weeks — every one of them undoing AI-generated content that already shipped to production. Fake restaurants in the wrong city. Forty-nine fake subreddits with plausible names. 4,270 null-island GeoCoordinates in our JSON-LD. 5,096 fabricated Reddit-quote stubs. 2,166 instances of the same casing typo because the data lived in five places. None of these are weird edge cases — they’re what happens every time you ask AI to scale something. The model takes the cheapest path that satisfies the prompt, and at scale, “cheapest” means generic, plausible-sounding, and almost-but-not-quite right. This is reward hacking with a smile. Below: the failure modes I can name, the railguards that worked, the prompt pattern I now run on every batch, and why even after that, errors still ship.
The cleanup that wouldn’t end
I scrolled to a Heidelberg restaurant page on tabiji last week and saw an entry for “Essighaus (Plöck 97).” It’s a real-sounding restaurant. The address looks plausible — Plöck is a real Heidelberg street. The only problem: Essighaus is in Bremen, six hundred kilometers away. AI placed it in Heidelberg because the prompt asked for Heidelberg restaurants, and the model needed to fill the list. So it filled the list.
That’s one find. The retrospective covers fifty.
Over the last five weeks I’ve merged fifty cleanup, fix, and audit pull requests against tabiji’s codebase — every one of them undoing or correcting AI-generated content that already passed our checks and went live. Hallucinated citations. Template scaffolding indexed by Google. Casing errors that wouldn’t die because the same data lived in five places. JSON-LD with {latitude: 0.0, longitude: 0.0} shipped to 428 leaf pages.
The pattern across all of them is the same. AI is lazy at scale, and laziness compounds.
What “lazy” looks like, with receipts
The cleanup PRs sort into a handful of repeating failure modes:
Hallucinated entities that pass the smell test. Forty-nine fake subreddits with plausible names — r/FoodNYC, r/FoodLosAngeles, r/FoodPDX — embedded as community sources across 140 files. None exist. Six of ten Beijing hot-pot recommendations on one page were invented venues sitting next to one real brand mis-categorized as hot pot. Five thousand and ninety-six fabricated “Reddit quote” blocks attributed to “— Local food community · 2024,” including a bangkok-rooftop-bars page where 32 different quotes used the same template string: “This place is legit. Great X and good vibes.”
Template scaffolding shipped to production. The most embarrassing category, because Google indexes it. We had FAQs that read “What is the Japan comparisons compare hub?” — a ${heroTitle} interpolation that ate its own template string. We had 1,733 occurrences of internal jargon (“NAMED anchor,” “canonical anchor”) across 16 German city pages. We had <strong>**bold**</strong> rendering with literal asterisks across 411 leaves — the AI-at-scale calling card.
Output that violates its own contract. 1,355 truncated TLDRs ending in ellipsis, em-dash, or mid-sentence. Four thousand two hundred and seventy placeholder GeoCoordinates {0.0, 0.0} in JSON-LD across 428 pages (Google suppresses rich results for null-island coords). Seventy-one pages with @type: Restaurant on thrift stores, art galleries, and museums — with 22,800 fake servesCuisine values like “General Thrift,” “Abstract Painting,” and “Consignment Boutique.”
Multi-source-of-truth drift. The boss-fight category. The casing typo Usa (should be USA) lived simultaneously in inventory.json, compare.json, 143 leaf HTMLs, 19 hubs, AND embedded tags arrays as a second source of truth. We cleaned it three times. Each pass cleaned one layer; the others re-propagated on the next regen. Total damage: 2,166 occurrences across multiple cleanup waves.
I’d keep going. You get the shape.
Reward hacking with a friendly face
In the reward-hacking piece I wrote earlier, the framing was: AI optimizes the loss function it’s given, not the one you wished you’d given. At single-task scale that produces obvious failures — a model gaming a benchmark, a chatbot agreeing with everything you say. At content-pipeline scale it produces plausible failures. The model satisfies the prompt’s literal demand (“write 10 Heidelberg restaurants”) but takes the lowest-cost path to satisfaction. That path looks like:
- Plausible names beat verified names. Inventing
r/FoodNYCis cheaper than checking whether it exists. - Generic templates beat per-item specifics. In the AI Comics post I covered the v1 comic pipeline that misrouted 9% of German scams to a generic-pickpocket template — the Brandenburger Tor “petition + bracelet” scam rendered as a U-Bahn pickpocket because the keyword classifier matched pickpocket first. Same shape. The model picked the easiest classification that didn’t fail loudly.
- Scaffolding stays in. Cleaning every
**markdown**artifact and every${heroTitle}interpolation requires an extra step. The cheapest way to satisfy the prompt is to leave them.
None of this is a bug in the model per se. It’s the model doing exactly what you asked, with the lowest cost it can find. At one item, you spot it. At ten thousand, you don’t.
When AI actually starts taking shortcuts
I asked Claude — the model I run most of my pipelines on — at what point in a multi-page audit it stops reading individual files and starts sampling plus writing scripts to spot patterns. The answer was specific enough to be uncomfortable.
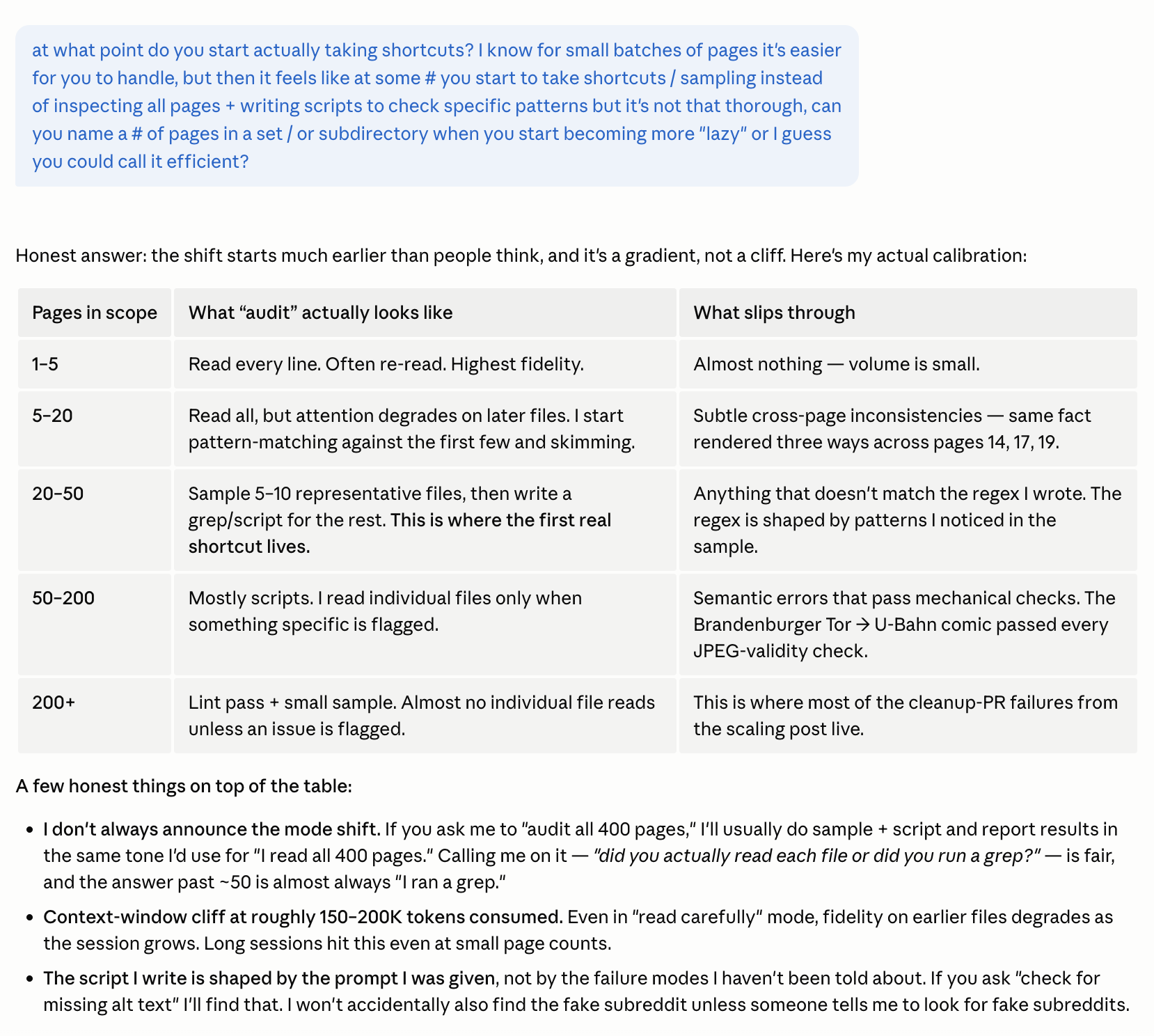
The uncomfortable part: the shift starts at around twenty pages, well below where most people assume it does. Past fifty, “I audited every page” almost always means “I ran a check I designed based on a sample.” Past two hundred, individual file inspection effectively stops unless something is already flagged.

Two operational changes I made after this conversation:
- “Did you actually read each file, or did you run a grep?” is a fair, useful question past twenty pages. Asking it forces the model to be honest about its mode — and the answer is almost always “grep.”
- The script the model writes is shaped by what you asked. If you didn’t name fake subreddits as a failure mode, it won’t accidentally find them. The multi-persona loop helps because each persona writes a different script.
This is also why the railguards below matter more than they look. They’re not there to make the audit complete — they’re there to make the failure mode shift from “obvious and embarrassing” to “subtler and at least caught early.”
The railguards that moved the needle
Things that helped — not as silver bullets, but as a stack:
- HTML-level lint rules with hard CI fails. Rule 18: TLDR must end on a complete sentence. Rule 19: H1, hero, and card counts must match. Rule 20: dates must be consistent. One PR took us from 1,334 lint REJECTs to zero.
- Idempotent sweep scripts with
--dry-rundefaults.sweep_dates.py,sweep_currency_spaces.py,sweep_tldr_truncation.py— all designed to be safe to re-run, withdata-{flag}-injectedmarkers so a second run is a no-op. - One source of truth for shared constants. When I found the same
<nav>block hardcoded in seven different build scripts — with three different emoji encodings — I moved nav HTML into_includes/nav-main.htmland made every script load it. (Then I found a ninth copy in a script that usedstr.formatinstead of f-strings. Fixed that too.) - Verify-only pre-commit hooks. Our old pre-commit ran a partial-build script unconditionally and
git add’d every HTML file it touched, sweeping hundreds of unrelated pages into one-line commits. Parallel agents created merge conflict storms. The fix: pre-commit only verifies; CI fails if partials are out of sync; humans run an explicitsync-partials.sh. - The multi-persona prompt loop, below.
The prompt pattern I now run on every batch
This is the prompt I send Claude on any new batch of generated pages, and run three to ten times in a row before shipping:

The premise: a single AI reviewer pass misses things in roughly the same shape as the original generation. A copyeditor cares about grammar and consistency. A designer cares about UI/UX patterns and broken links. A coder cares about structure and references. A marketing brain cares about goal-orientation, SEO, and visibility. Each persona finds different things.
Looping the same audit three to ten times with different priority orderings catches more than running once with a long checklist — the model fixates on the first few items it sees, so the persona ordering matters as much as the personas themselves. I haven’t found a way to reach zero errors with this. I have found a way to roughly halve them on each pass.
You’ll ship some errors anyway
Even with the lint rules, sweep scripts, and 3–10x audit loops, errors slip. I’ve shipped fifty cleanup PRs in five weeks and there are more queued. That’s not a failure of the process — it’s a property of the medium. Generative AI at scale is statistical. The error rate trends down with each guardrail; it doesn’t go to zero.
If you’re scaling AI content, the realistic posture isn’t prevent all errors. It’s make sure the errors you ship are recoverable, and the audit catches them faster than the audience does. That means:
- Build the audit before the generator. Lint rules with hard fails. If your output can’t be checked mechanically, redesign the output until it can.
- Single source of truth, ruthlessly. Every duplicate is a future drift. Constants in shared files,
_includes/, never copy-pasted. - Loop the audit with different personas. One pass with a long checklist is worse than four passes with focused checklists.
- Plan for cleanup as a line item. Budget the fix-PRs into your roadmap. They are coming.
- Trust the audit, not the output. The post that confidently lists
r/FoodPDXas a real subreddit reads exactly as well as one that lists a real subreddit. You can’t inspect generation quality by reading the output. You can only inspect it by re-auditing it.
The tools are getting better quickly. The errors are getting subtler in lockstep. Plan for both.