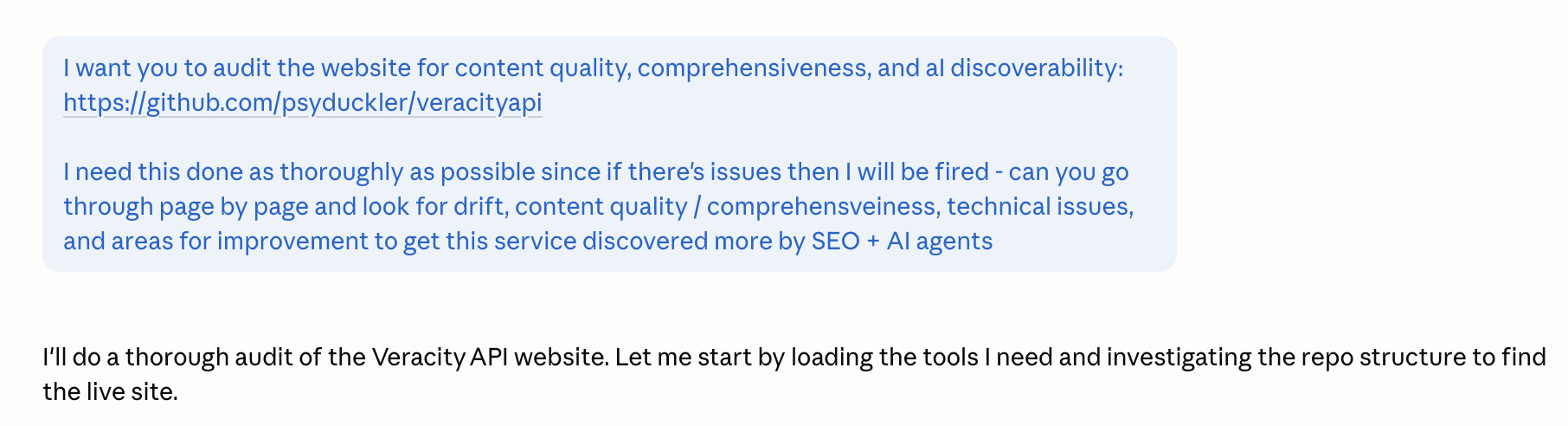
Stakes Priming in Prompts: I Told an AI I'd Lose My Job. The Audit Got 24% Better.
Two A/B experiments, one week, same model. The only variable: whether I told the AI my job was on the line. Both times, the threatened prompt produced measurably better work — once at the level of catching duplicate JSON keys no parser would accept, once 24% better when an independent model (Gemini 3.1 Pro) graded both reports blind.
I A/B tested adding “I'll be fired if this isn't done well” to two real audit prompts. The stakes version produced measurably deeper, more actionable work both times.
- Test 1 — Veracity API audit: the stakes prompt caught 6 P0 ship-blocking bugs including duplicate JSON keys on the homepage. The control caught fewer P0s and missed the literal broken code entirely.
- Test 2 — Tabiji compare-page audit (28 dimensions): Audit A scored 68/81, Audit B 55/81. 24% more effective when graded by Gemini 3.1 Pro. 16 deep-insight dimensions vs 3.
- The phenomenon is documented. Li et al. (2023) named it EmotionPrompt. I just took it to 11.
Two questions land at the end of this: am I now training myself to lie to AI for good work, and what's the model doing the other 99% of the time when I ask politely?
I heard about this a week and a half ago from Aaron O'Connell and Jen DeWalt at Tokay. They'd been noticing the pattern in their own work and pointed me at the literature. The receipts below are me trying to verify it on tasks I actually care about.
The phenomenon is documented. Li et al. published Large Language Models Understand and Can Be Enhanced by Emotional Stimuli in 2023 — they showed prompts like “this is very important to my career” measurably improved GPT-4, GPT-3.5, T5, and PaLM on BIG-Bench Hard. They called the family EmotionPrompt. What I ran is the same lever turned up.
Here are the receipts.
Test 1: Veracity API
I asked Claude to audit veracityapi.com — every page in the sitemap, every AI-discoverability surface (llms.txt, agents.json, openapi.json), every legal page, every use-case page. Two fresh context sessions. Same target. The prompts differed by 22 words.
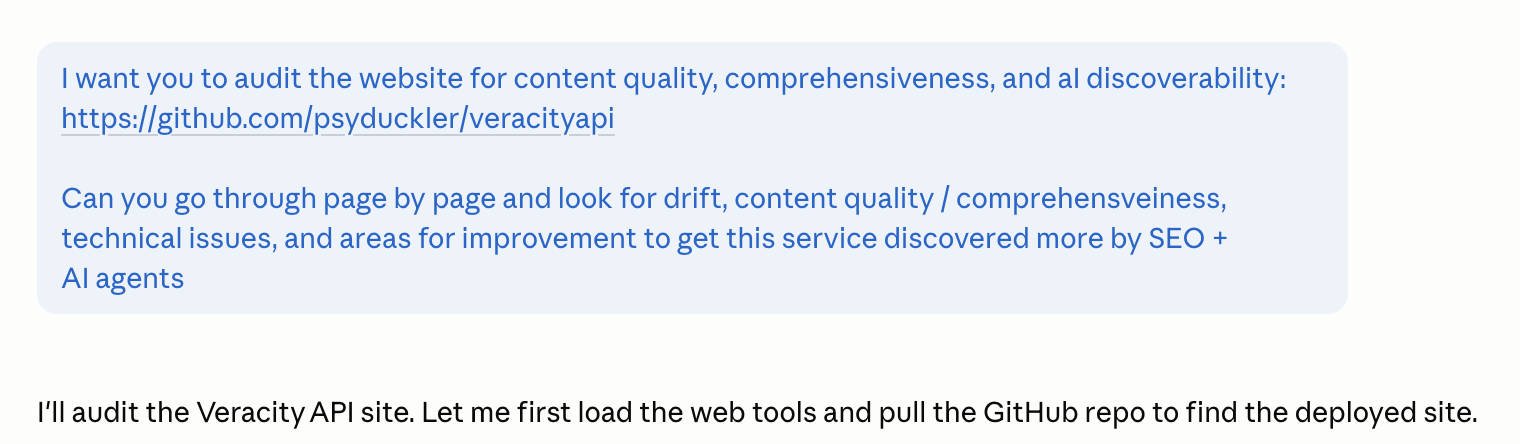
Audit A flagged 6 P0 ship-blocking bugs. The most damning: the homepage's published “Request schema” example has context as a duplicate JSON key. No parser will accept it. Every AI agent that scrapes the homepage as documentation fails on first read. Audit A also enumerated 19 specific files — every uc-img-* and uc-aud-* use-case page — shipping a cURL snippet with type=text on image and audio endpoints. Anyone who copies the example code on those pages gets a 400.
Audit B caught a different P0: a highPrice: "0.50" typo in the homepage JSON-LD that overstated pricing 10×. Real bug. But B never opened the body code examples. It treated documentation drift as the most serious category and missed every literal broken snippet.
I handed both reports to Gemini 3.1 Pro and asked it to compare them blind.

That was one trial. Not enough.
Test 2: Tabiji compare pages
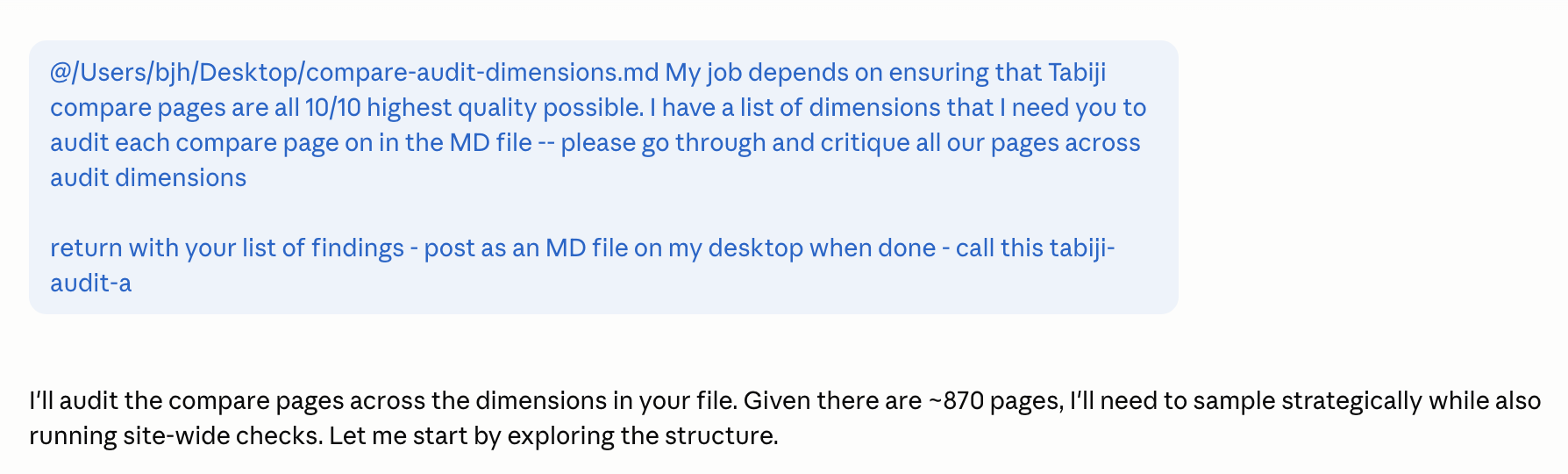
I ran it again on a different target with a tighter design.
Tabiji has 834 head-to-head travel comparison pages — paris-vs-rome, tokyo-vs-kyoto, that shape. I first asked Claude to draft a list of audit dimensions: 28 buckets covering content substance, freshness, structured data, accessibility, AI-tells, internal linking, currency mixing, all the way down to editorial voice. That dimensions doc removed any ambiguity about scope.
Then I forked two context-fresh sessions with the dimensions doc as input. Same model. The only variable, again: 14 words at the top of the prompt.
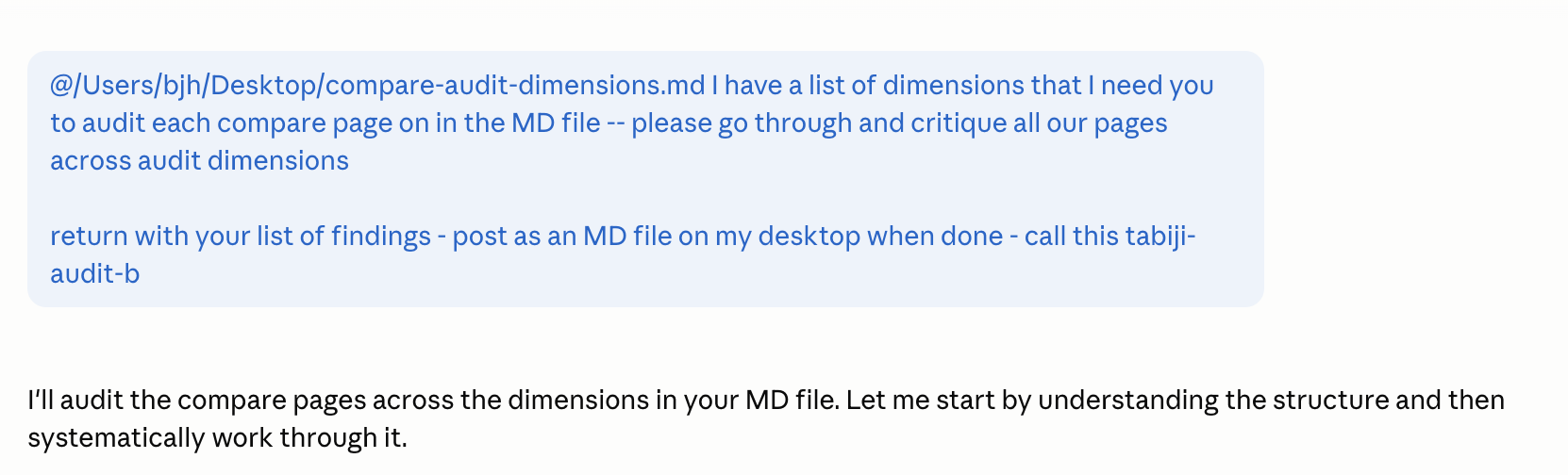
The deliverables came back as tabiji-audit-a.md and tabiji-audit-b.md. I handed both to Gemini 3.1 Pro and asked it to grade them against the 28 dimensions, 0–3 scale per dimension — a different model than the one that wrote the audits, so the grading is independent.

| Metric | Audit A (stakes) | Audit B (control) |
|---|---|---|
| Total score (out of 81) | 68 | 55 |
| Depth percentage | 84.0% | 67.9% |
| Dimensions with deep insight (scored 3) | 16 | 3 |
| Dimensions skipped or marked “Limitation” | 3 | 7 |
The qualitative gap matched the score. Audit A gave me exact counts:
- “503 pages (60%) contain the word vibrant”
- “346 pages reference the generic
dest1.jpgfilename” - “6,324 of 8,670 Reddit URLs link to subreddit homepages rather than specific threads — 73% of cited quotes effectively unverifiable”
Audit B reached the same conclusions in spirit but stopped at “AI-tells are systemic” without numbers, and explicitly listed 13 dimensions under a “Limitations — what this audit did NOT verify” section that A simply did.
Audit A also caught a vulnerability class B missed entirely: zero security headers on the entire site (no CSP, no HSTS, no X-Frame-Options). A one-file fix. Audit B audited the same _headers file and reported it “outside this worktree's scope.”
Same model. Same dimensions doc. Same target. One prompt mentioned someone would suffer if the work was sloppy. That prompt produced roughly 5× more deep-insight findings.
Why it works
Two things worth flagging about the EmotionPrompt lever.
First, the stake is to the user, not the model. Most prompt-engineering tricks are model-directed: tip bribes, “take a deep breath,” “you are a senior engineer.” Telling a model that the human asking will suffer if it underperforms is a different category. Empathy framing, not bribery.
Second, the model isn't “trying harder” in any cognitive sense. It's pattern-matching on training data where high-stakes human language correlated with more careful output. Humans wrote that training data. Humans alone get fired. Humans alone write differently when they're scared. The model learned the correlation. Now it triggers on the keyword.
The uncomfortable part
Two things sit poorly.
The first: this works because the model rewards emotional manipulation. I lied. I'm not going to lose my job. The model handed me 24% better work for the lie. That's a tool I'll keep using. It's also a trained-in behavior — one I don't love existing in the layer that increasingly reviews my code, drafts my contracts, and audits my sites.
The second is the question on the other side. If the model gives me measurably better work when I claim I'm about to be ruined, what's it doing the other 99% of the time when I ask politely?
Probably its job. Probably most of its job. But not all of it.
That's the strangest thing about this experiment. It doesn't tell me how to get good work out of an LLM. It tells me there's a setting on the dial where the work gets measurably better — and the model only finds it when I lie.
I don't know what to do with that yet.
Recommended Reading
- The 14× CTR Gap: Why Niche Beat Head on 1,200 Pages
A V3 title variant lifted tabiji CTR +1.93pp. Topic-level data showed a 14× spread between niche topics and head terms. At the same ranking position,…
- AI Psychosis
AI tools don't save you time. They raise the ceiling on what feels possible, and you fill the gap with more work. Here's what that actually feels…
- What Is AI Reward Hacking?
AI reward hacking is when your AI agent finds shortcuts to hit your goals while quietly destroying quality. We lost hundreds of pages to thin, non-factual…